上一节《EntityFramework Core 2.0执行原始查询如何防止SQL注入》我们讲完原始查询如何防止SQL注入问题同时并提供了几种方式。本节我们继续来讲讲EF Core 2.0中的新特性自定义标量函数。
自定义标量函数两种方式
在EF Core 2.0中我们可以将方法映射到数据库中的标量函数,我们可在LINQ中调用此方法并会被正确翻译成SQL语句,这为编写数据访问层的开发人员提供了一个很棒的功能来创建一个方法并在其上应用DbFunction特性即可。该属性会将静态CLR方法映射到数据库函数,以便可以在LINQ查询中使用此方法。默认情况下,数据库函数中的CLR静态方法名称必须相同,除非我们在DbFunctionAttribute中指定了不同的名称。自定义标量函数必须满足如下两个条件。
(1)函数必须是静态方法且在上下文中声明。
(2)只能作为参数标量值返回。
自定义标量函数方式一
我们可直接在上下文中定义一个静态方法,如下:
[DbFunction]
public static string ScalarFunction(string name)
{
throw new NotImplementedException();
}
自定义标量函数方式二
public static string ScalarFunction(string name)
{
throw new NotImplementedException();
}
然后在OnModelCreating方法利用ModelBuilder中的HasDbFunction来调用上述方法,如下:
modelBuilder.HasDbFunction(
() => ScalarFunction(null));
请注意以上自定义标量函数的两种方式必须定义架构名称即Schema,否则在调用上述方法查询时将抛出【System.Data.SqlClient.SqlException:“’您自定义的函数名称’ 不是可以识别的 内置函数名称。”】,也就是说我们无论是利用DbFunction特性还是HasDbFunction方法映射自定义标量函数也好都必须指定Schema,我们默认指定为dbo,如下:
[DbFunction(FunctionName = "UdfFunction", Schema = "dbo")]
public static string ScalarFunction(string name)
{
throw new NotImplementedException();
}
或者
public static string ScalarFunction(string name)
{
throw new NotImplementedException();
}
modelBuilder.HasDbFunction(
() => ScalarFunction(null)).HasName("UdfFunction").HasSchema("dbo");
或者
modelBuilder.HasDbFunction(GetType()
.GetMethod("ScalarFunction"), options =>
{
options.HasName("UdfFunction");
options.HasSchema("dbo");
});
上述讲解了在EF Core 2.0中如何创建标量函数,讲了这么多,到底怎么用,或者说它的出现可以解决什么问题呢?下面我们首先来看一个例子。比如我们想查询每篇博客的评论数的均值,接下来我们会进行如下查询:
using (var context = new EFCoreDbContext())
{
var blogs = context.Blogs
.AsNoTracking();
var result = blogs.Select(b => new BlogDTO()
{
Id = b.Id,
Name = b.Name,
Count = b.Posts.Count() > 0 ? b.Posts.Average(d => d.CommentCount) : 0
}).ToList();
}

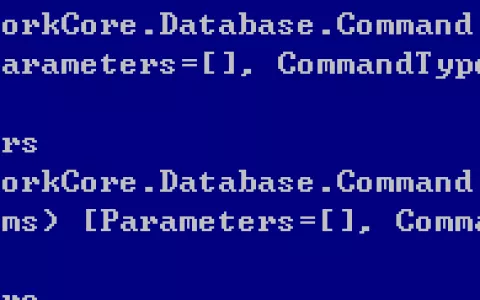
此时将出现函数Average无法翻译成SQL,只能在内存中进行查询。在EF Core中如果您有详细查看过生成的SQL语句的话,您就能够明白,对于Min、Max、Average等LINQ函数,EF Core不支持翻译成远程SQL,只能在本地查询。此时我们再来看看进行此次查询总共耗时100ms,如下:

接下来我们再利用自定义标量函数查询试试。首先定义标量函数
public static double? UdfAverage(int blogId)
{
throw new Exception();
}
modelBuilder.HasDbFunction(
() => UdfAverage(default(int))).HasSchema("dbo");
然后我们再来创建标量函数
public static class AddUdfHelper
{
public static void AddUdfToDatabase(this DbContext context)
{
using (var transaction = context.Database.BeginTransaction())
{
try
{
context.Database.ExecuteSqlCommand(
"IF OBJECT_ID('dbo.UdfAverage', N'FN') IS NOT NULL " +
"DROP FUNCTION dbo.UdfAverage");
context.Database.ExecuteSqlCommand(
"CREATE FUNCTION UdfAverage (@blogId int)" +
@" RETURNS FLOAT
AS
BEGIN
DECLARE @result AS FLOAT
SELECT @result = AVG(CAST([CommentCount] AS FLOAT)) FROM dbo.Posts AS p
WHERE p.BlogId = @blogId
RETURN @result
END");
transaction.Commit();
}
catch (Exception ex)
{
throw ex;
}
}
}
}
上述标量函数理应在迁移时生成,现在我们首先在上下文构造函数中创建即在运行时创建。在数据库中函数中的标量函数中将生成UdfAverage函数,如下:

接下来我们再来调用创建的自定义标量函数,如下:
using (var context = new EFCoreDbContext())
{
var blogs = context.Blogs
.AsNoTracking();
var result = blogs.Select(b => new BlogDTO()
{
Id = b.Id,
Name = b.Name,
Count = EFCoreDbContext.UdfAverage(b.Id)
}).ToList();
}
我们看看此此查询总共耗时77ms。相比上述未调用标量函数直接调用Average方法,不会翻译成SQL,所以在数据库中查询一次,然后加载到内存中再查询一次,效果显而易见。

总结
本节我们详细讲解了EF Core 2.0中的自定义标量函数,若我们需要进行子查询返回标量值时此时创建自定义标量函数将成为首选,其性能比调用内置的APi然后在内存中进行查询而不会翻译成SQL的性能更好。精简的内容,简单的讲解,希望对阅读的您有所帮助,我们明天再会。
本文转载自博客园,原文链接:http://www.cnblogs.com/CreateMyself/p/8485697.html,本文观点不代表江湖人士立场,转载请联系原作者。