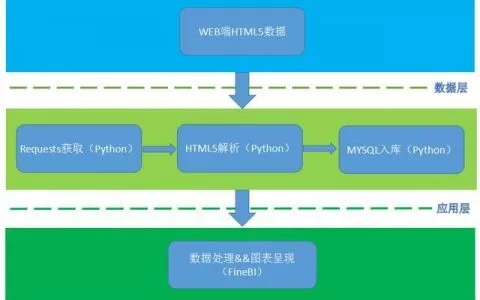
本文介绍Python爬取智联招聘数据,这是源自2020知乎上的转载文章,这一篇主要是讲爬取智联招聘数据过程中踩过的坑。因为爬虫程序具有时效性,之前可以爬取的程序现在爬取不成功也是正常的。
 1")
Python爬取智联招聘数据
但由于博客的转载抄袭较多,使得一些近期的博客也会出现爬取不成功的现象。就目前看到的博客而言,网络上关于智联招聘爬虫的程序均不可用。(本系列的终篇将会给出一种目前可行的爬取方案),明确下爬虫的目的,主要是爬取岗位的招聘公司、薪资水平、学历要求等数据。
坑一:使用requests库爬虫
requests库是python爬虫的一个比较基础的库,通过伪装成浏览器向服务器请求数据,获得浏览器返回的数据。
import requests
#from lxml import etree
url = 'https://sou.zhaopin.com/?jl=530&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3'
#将爬虫伪装成浏览器请求网页数据
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}
r = requests.get(url, headers=headers)
print(r.status_code)#200 表示请求成功
print(r.text)
通过print(r.text)可以发现打印出来的内容是源码内容,不包含想要爬取的岗位信息。
收获:智联招聘网站是动态网页,源码和呈现的内容不同,不能通过向requests库请求获得数据。通过部分博客发现selenium可以用于爬取动态网页。
坑二:使用selenium爬取
selenium是一个操作浏览器访问服务器的库,selenium能够爬取动态网页的原理是,通过操作浏览器的请求,浏览器能够执行服务器返回数据中的JavaScript代码,从而使得能够获取到想要的数据。
from selenium import webdriver #浏览器驱动 import time from bs4 import BeautifulSoup #网页解析 driver = webdriver.Chrome() url = 'https://sou.zhaopin.com/?jl=530&kw=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&kt=3' driver.get(url) time.sleep(5) soup = BeautifulSoup(driver.page_source, "lxml") #解析网页 driver.quit() print(soup) #查看服务器返回的数据
print(soup)的内容和requests库的内容一样,这时候获取的还是网页源码,使用所谓的“可见即可爬”的selenium仍然没能获取到想要的数据。具体原因涉及到前端开发的内容,在这里不展开论述。
收获:selenium不是万能的,但确实是个好工具
坑三:分析API端口爬取数据
目前网络上更多的是这种方法,在分析API端口前首先需要确定想要爬取的数据到底在哪里?
- 打开谷歌浏览器,直接输入url,或者打开智联招聘网站,搜索框输入“数据分析师”等进行搜索
- 在“更多工具”中打开开发者工具
- 按照下面步骤寻找数据(如果没有红色框内链接的话,F5刷新页面)
- 找到数据,在以sou?开头的链接的response中就包含了想要爬取的数据
 2")
 3")
找到数据后,在以sou?开头的链接中,可以找到数据的API接口,形式极其复杂:
https://fe-api.zhaopin.com/c/i/sou?at=eebd47f3434240b085040d4f6b149749&rt=6ffefe8cf6df4c5eb0018b2504fd3385&_v=0.89139877&x-zp-page-request-id=e13c913dbd43495b8cd6c7bff98e9055-1591626444871-43840&x-zp-client-id=9a7d8a4b-e5c6-45b0-aece-8059d08a57c1&MmEwMD=5Q9QRCjOiRKcb.VFVo1vfO.RVObc3_pjxbJ4l4dDOUtpeciY4pC5VZKYF7KjPUMSZH_6kARIuVMincWAL3z5ahkiRqqrhCecHETc_DThVY_g78z_t2AxGvmFxVMHjX0FWPBfJ7s5Uq7tASK87eGjGuV6gY1C9H.FDw6HiI3PQ3uUSMTMShGS8yLXbq3LDeyVQ23pkmzecZsaWgZ902mSwmxfpEpHmrIZ4j.drhpCqqeVHE.Y5TEkzptfBVJLWmjGmO9xZMeSM6N2DF96avpNmFbSlesiCivoHuncYG_GahyZewaha8IPHQaul5WLh4coFLCqA_Zf_6NaPw65BR7Z6lIg8ucB4lJHwPOw9BwMCdI6a2xbai5k3lwDvamYnXU4f4B8QxFN461j69EdMSxk_kr02
直接访问链接发现并无数据,远不是其他使用API接口爬取的链接形式,说明智联招聘对该API进行了加密,估计是包含了时间加密,使得通过API爬取数据,基本不可行,除非能够解密上述链接。
收获:此路不通! 但是找到了想要爬取的数据源。
笨办法:如何采集数据
既然已经在坑三中找到了想要爬取的数据,可以发现这些数据是一个json文件,那直接把json复制粘贴下来是不是就可以了,说干就干。
对于某个城市的某个岗位,智联招聘只提供12*90的岗位信息(12个分页,每页90条招聘记录),共计1080个岗位信息。一个json文件包含了一页的数据,也就是90个岗位信息,想要收集智联招聘对于某个岗位的信息,只需要复制粘贴12次即可,在10分钟内即可完成。爬虫嘛,收集数据为目的,手动采集不丢脸~
复制粘贴到txt文件就可以。
 4")
接下来就是使用python解析json文件即可,将相应代码贴在下方,供大家使用。
import json
import pandas as pd
data_final = pd.DataFrame()
error_data = pd.DataFrame()
for i in range(1,13):
with open(str(i)+".txt",'r') as file_open:
data = json.load(file_open)
for j in range(0,90):
try:
jobname=data['data']['results'][j]['jobName']
companyname=data['data']['results'][j]['company']['name']
companysize=data['data']['results'][j]['company']['size']['name']
cityname=data['data']['results'][j]['city']['items'][0]['name']
try:
districtname=data['data']['results'][j]['city']['items'][1]['name']
except Exception:
districtname = ''
salary=data['data']['results'][j]['salary']
edulevel = data['data']['results'][j]['eduLevel']['name']
workingExp = data['data']['results'][j]['workingExp']['name']
positionURL = data['data']['results'][j]['positionURL']
data_slice = [[jobname,companyname,companysize,
cityname,districtname,salary,
edulevel,workingExp,positionURL]]
data_slice = pd.DataFrame(data_slice)
data_final = data_final.append(data_slice)
except Exception:
error_data = error_data.append(pd.DataFrame([[i,j]]))
print(i)
由于可能存在部分岗位记录不规范,导致不能采集相应的数据,所以使用error_data进行记录,再简单看下json文件修正下代码即可。
总结
这篇文章主要是对自己踩过的坑进行总结,避免后来者再次浪费时间。针对少数据量的需求,提出通过复制粘贴的方法进行,简便快捷。但如果需要大量的数据该方法就不再适用。在接下来两期中将逐步自动化上述过程,提供一种可以采集大量数据的方法。本文首发公众号“数据科学家进阶之路”,主要专注数据分析所需的技能,通过相应的案例熟悉模型算法,通过实际的业务事例熟悉商业逻辑,通过读书积累分享思维方式。
本文转载自知乎,原文地址:https://zhuanlan.zhihu.com/p/149760553

【江湖人士】(jhrs.com)原创文章,作者:江小编,如若转载,请注明出处:https://jhrs.com/2018/24367.html
扫码加入电报群,让你获得国外网赚一手信息。