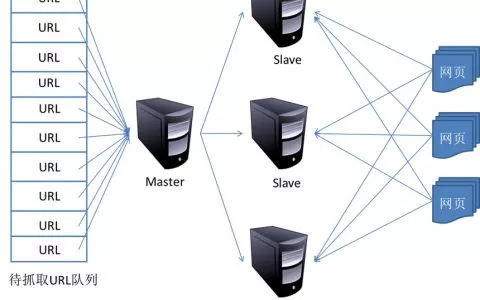
什么是网络爬虫技术?反爬虫技巧解读,Web是一个开放的平台,这也奠基了Web从90年代初降生直至今日快要30年来兴旺的成长。然而,正所谓成也萧何败也萧何,开放的特型、搜刮引擎以及简单易学的HTML、CSS手艺使得Web成为了互联网范畴里最为风行和成熟的消息传布前言。
但现在作为贸易化软件,Web这个平台上的内容消息的版权却毫无包管,由于比拟软件客户端而言,你的网页中的内容能够被很低成本、很低的手艺门槛实现出的一些抓取法式获取到,这也就是这一系列文章将要切磋的话题收集爬虫。
 1")
有良多人认为Web该当一直遵照开放的精力,呈此刻页面中的消息该当毫无保留地分享给整个互联网。然而我认为,在IT行业成长至今天,Web曾经不再是昔日阿蒙受和PDF一争高下的所谓“超文本”消息载体了,它现在是以一种轻量级客户端软件。
桌面软件成长到今天曾经面临的问题,Web也不得不面临知识产权保护的问题,试想若是原创的高质量内容得不到保护,抄袭和盗版,采集横行整个互联网,这其实对Web生态是毁灭性的打击,也很难激励更多的优良原创内容的产生。
什么是网络爬虫技术
未授权的爬虫抓取法式是Web原创内容生态的一大首恶,因而要保护网站的内容,网络爬虫软件起首就要考虑若何反爬虫。
最简单的爬虫,是几乎所有服务器端、客户端编程言语都支撑的http请求,只需向方针页面的url倡议一个http get请求,即可获获得浏览器加载这个页面时的完整html文档,这被我们称之为“静态网页”。
作为防守的一方,服务器端能够按照http请求头中的User-Agent来检查客户端能否是一个合法的浏览器法式,亦或是一个脚本编写的抓取法式,从而决定能否将实在的页面消息内容下发给你。
这当然是最小儿科的防御手段,爬虫作为进攻的一方,完全能够伪造User-Agent字段,以至,只需你情愿,http的get方式里, request header的 Referrer 、 Cookie 等等所有字段爬虫都能够垂手可得的伪造。
此时客户端能够操纵浏览器http头,按照你声明的本人的浏览器厂商和版本(来自 User-Agent ),来辨别你的http header中的各个字段能否合适该浏览器的特征,如不合适则作为爬虫看待。这个技术有一个典型的使用,就是PhantomJS1。低版本中,因为其底层使用了Qt框架的收集库,因而http头里有明显的Qt框架收集请求的特征,能够被服务器端间接识别并拦截。
 2")
爬虫检测机制
除此之外,还有一种愈加反常的服务端爬虫检测机制,就是对所有等侯的页面http请求,在 http response 中种下一个 cookie token ,然后在这个页面内异步施行的一些ajax接口里去校验来访请求能否含有cookie token,将token回传回来则表白这是一个合法的浏览器来访。
若是你不按照token间接请求一个接口,这也就意味着你没请求过html页面间接向本应由页面内ajax访问的接口发起了异步请求,这也明显证了然你是一个可疑的爬虫。知名电商网站amazon就是采用的这种防御策略。
现代浏览器赋与了JavaScript强大的能力,因而我们能够把页面的所有焦点内容都做成js异步请求,ajax 获取数据后呈现在页面中的,这明显提高了爬虫抓取内容的门槛。根据这种做法,我们把对爬虫与反爬虫的对阵疆场从服务端转移到了客户端浏览器中的js运转时,接下来说一说运用客户端js运行时的爬虫抓取技术。
方才谈到的各类服务器端的校验,对于通俗的python、java言语编写的http抓取法式而言,具有必然的技术门槛,终究一个web使用对于未授权抓取者而言是黑盒的,很多工具需要一点一点去测验验证,而浪费大量人力物力开发好的一套抓取法式,web站作为防守一方只需等闲调整一些策略,攻击者就需要再次花费很多的时间去重新破解爬虫抓取逻辑。
此时就需要利用headless browser了,这是什么技术呢?其实说白了就是,让程序能够操作浏览器去请求网页,如许编写爬虫的人能够通过使用用浏览器提供的接口合法方式调用api去实现复杂的网页抓取逻辑。
其实近年来这曾经不算是什么新颖的技术了,目前有基于webkit内核的PhantomJS,基于Firefox浏览器内核的SlimerJS,以至基于IE内核的trifleJS。
这些headless browser法式实现的原理其实是把开源的一些浏览器内核C++代码加以重写和封装,实现一个简略单纯的无GUI界面衬着的browser法式。但这些项目遍及具有的问题是,因为他们的代码基于fork官方webkit等内核的某一个版本的主干代码,因而无法跟进一些最新的css属性和js语法,而且具有一些兼容性的问题,不如真正的release版GUI浏览器。
这此中最为成熟、利用率最高的当属PhantonJS了,对这种爬虫的识别我之前曾写过一篇博客,这里不再赘述。PhantomJS具有诸多问题,由于是单进程例子,没有需要的沙箱庇护,浏览器内核的安全性较差。
headless chrome可谓是headless browser中独树一帜的大杀器,因为其本身就是一个chrome浏览器,因而支撑各类新的css衬着特征和js运转时语法。
浏览器指纹检查技术
基于这些的手段,爬虫作为进攻的一方能够绕过几乎所有服务端的校验逻辑,可是这些爬虫在客户端的js运转时中仍然具有着一些马脚,诸如:
基于以上的一些浏览器特征的判断,根基能够通杀市道上大大都headless browser法式。在这一点上,现实上是将网页抓取的门槛提高,要求编写爬虫程序的开发者不得不阅读浏览器内核的C++代码,从头编译一个浏览器,而且,以上几点特征是对浏览器内核的改动其实并不小。
更进一步,我们还能够基于浏览器的UserAgent字段描述的浏览器品牌、版本型号消息,对js运转时、DOM和BOM的各个原生对象的属性及方式进行查验,察看其特征能否合适该版本的浏览器所应具备的特征。
这种案例被称为浏览器指纹检查技术,依托于大型web站对各型号浏览器api消息的收集。而作为编写爬虫法式的进攻一方,则能够在headless browser运转时里预注入一些js逻辑,伪造浏览器的特征。
别的,在研究浏览器端操纵js api进行robots browser detect时,我们发觉了一个有趣的小技巧,你能够把一个预注入的js函数,伪装成一个native function,来看看下面代码:
 3")
爬虫进攻方可能会预注入一些js方式,把原生的一些api外面包装一层proxy function作为hook,然后再用这个假的js api去笼盖原生api。若是防御者在对此做查抄判断时是基于把函数toString之后对[native code]的检查,那么就会被绕过。所以需要更严格的检查,由于bind(null)伪造的方式,在toString之后是不带函数名的。
目前的反爬取、机器人检查手段,最靠得住的仍是验证码技术。但验证码并不料味着必然要强迫用户输入连续串字母数字,也有良多基于用户鼠标、触屏(挪动端)等行为的行为验证技术,这此中最为成熟的当属Google reCAPTCHA。
基于以上诸多对用户与爬虫的识别区分技术,网站的防御方最终要做的是封禁ip地址或是对这个ip的来访用户施以高强度的验证码策略。如此一来,进攻方不得不采办ip代办署理池来抓取网站消息内容,不然单个ip地址很容易被封导致无法抓取。抓取与反抓取的门槛被提高到了ip代理池经济费用的层面。
robots机制
除此之外,在爬虫抓取技术范畴还有一个“白道”的手段,叫做robots和谈。你能够在一个网站的根目次下拜候/robots。txt,好比让我们一路来看看github的机械人和谈,Allow和Disallow声了然对各个UA爬虫的抓取授权。
不外,这只是一个君子和谈,虽具有法令效益,但只可以或许限制那些贸易搜刮引擎的蜘蛛法式,你无法对那些“野爬快乐喜爱者”加以限制。
对网页内容的抓取与反制,必定是一个魔高一尺道高一丈的猫鼠游戏,你永久不成能以某一种手艺完全封死爬虫法式的路,你能做的只是提高攻击者的抓取成本,并对于未授权的抓取行为做到较为切确的获悉。

【江湖人士】(jhrs.com)原创文章,作者:江小编,如若转载,请注明出处:https://jhrs.com/2018/25168.html
扫码加入电报群,让你获得国外网赚一手信息。